February 19, 2026




Traditional A/B testing measures click-through rates and conversions on your own website. AI search optimization requires a fundamentally different testing approach—you're testing whether AI platforms cite, recommend, and feature your content in their responses. Without systematic testing methodology, you can't determine which content formats, structures, and optimization techniques actually improve AI visibility.
According to RevvGrowth's AI Overviews analysis, pages with FAQ schema or HowTo schema get cited at roughly twice the rate of pages without structured data, assuming equal content quality. This insight only emerges through rigorous testing—comparing similar content with and without specific optimizations.
Standard web analytics can't measure AI citation outcomes.
According to SEO One Click's 2026 predictions, 54% of AI Overview citations overlap with pages ranked organically, meaning 46% come from sources that weren't top-ranked on Google at all. This unpredictability makes systematic testing essential—traditional ranking doesn't guarantee AI visibility.
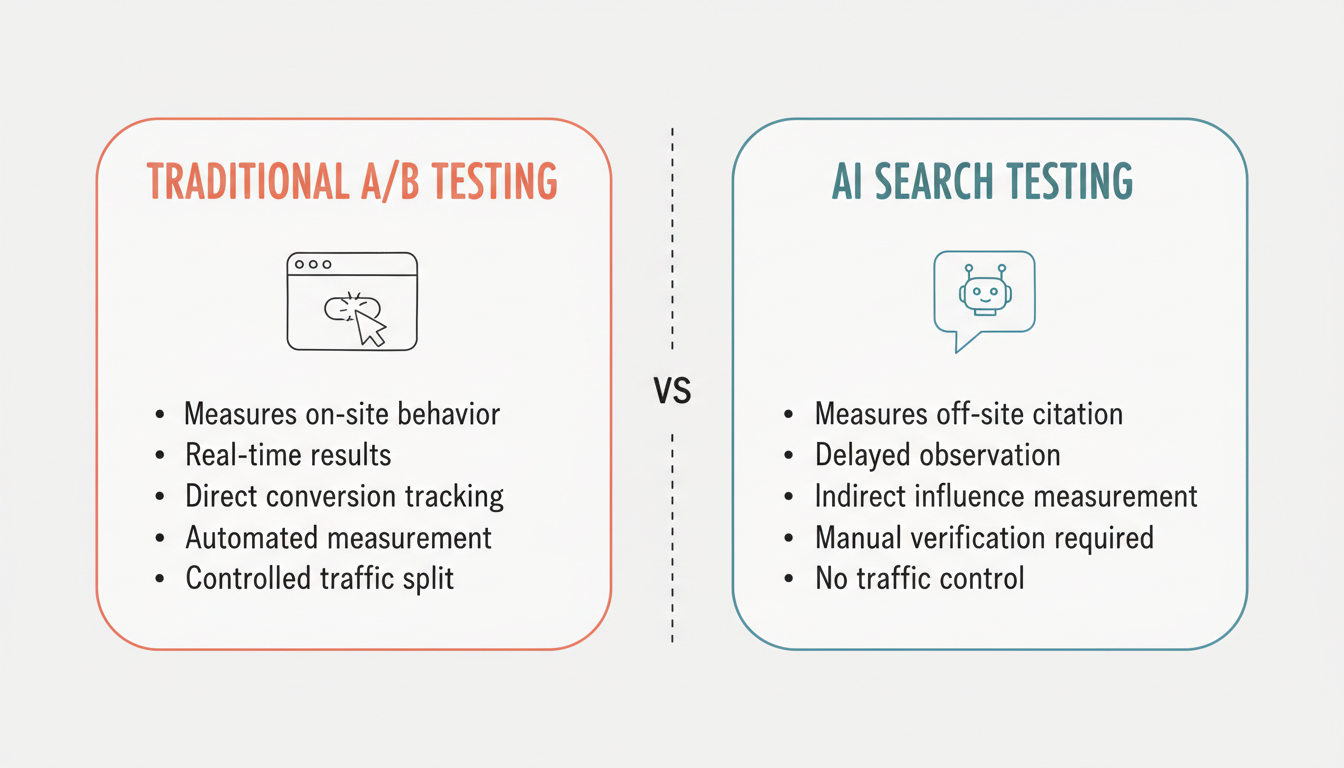
Key differences from traditional testing:
Traditional A/B Testing | AI Search Testing |
Measures on-site behavior | Measures off-site citation |
Real-time results | Delayed observation |
Direct conversion tracking | Indirect influence measurement |
Controlled traffic split | No traffic control |
Automated measurement | Manual verification required |
Start with systematic query testing across platforms.
According to ALM Corp's AI ranking guide, manual testing involves systematically asking target questions across AI platforms and documenting results—whether your brand appears, which competitors get cited, what sources AI platforms prefer, and how responses vary across ChatGPT, Claude, Gemini, and Perplexity.
Manual testing framework:
AI Citation Testing Process
├── Query Selection
│ ├── Identify 20-30 high-priority queries
│ ├── Include brand-specific questions
│ ├── Cover industry/topic questions
│ └── Mix informational and commercial intent
│
├── Platform Coverage
│ ├── ChatGPT (with browsing enabled)
│ ├── Perplexity AI
│ ├── Google AI Overviews
│ ├── Claude (with search)
│ └── Microsoft Copilot
│
├── Documentation
│ ├── Whether cited (yes/no)
│ ├── Citation position
│ ├── Sentiment of mention
│ ├── Competitors mentioned
│ └── Source types cited
│
└── Testing Cadence
├── Baseline measurement
├── Monthly tracking
├── Post-optimization checks
└── Competitive monitoringTest which formats earn citations most effectively.
According to eLearning Industry's AI optimization guide, iterative testing helps identify what works for AI visibility. Structured data, featured snippet optimization, and content format all influence citation rates. When implementing on-page AEO optimization, format variations directly impact whether AI platforms extract and cite your content.
Format variables to test:
Format Element | Variation A | Variation B | Measurement |
Answer position | Opening paragraph | Mid-content | Citation frequency |
List format | Numbered | Bulleted | Extraction rate |
Definition style | Single sentence | Multi-sentence | Quote selection |
Schema type | FAQ | HowTo | Rich result appearance |
Content length | Concise (800 words) | Comprehensive (2000+) | Citation context |
Structured data directly impacts citation rates.
Schema testing approach:
Schema types to test:
Understanding schema markup alignment for AEO helps you implement the right structured data types for maximum citation impact.
Focus experiments on high-impact elements.
According to Medium's Perplexity testing study, testing 112 startups revealed that Reddit mentions (+0.40 correlation), Product Hunt presence (+0.37), and referring domains (+0.32) correlated most strongly with Perplexity discovery—while technical GEO optimization showed essentially zero correlation.
High-impact test variables:
Testing Priority Matrix
├── High Impact, Easy to Test
│ ├── Schema markup presence
│ ├── Answer positioning
│ ├── Definition formatting
│ └── List structure
│
├── High Impact, Harder to Test
│ ├── Third-party mentions
│ ├── Reddit discussions
│ ├── Backlink profile
│ └── Brand authority signals
│
├── Medium Impact
│ ├── Content length
│ ├── Update frequency
│ ├── Internal linking
│ └── Media inclusion
│
└── Lower Impact (Per Research)
├── Keyword density
├── Meta descriptions
├── URL structure
└── Page speed alone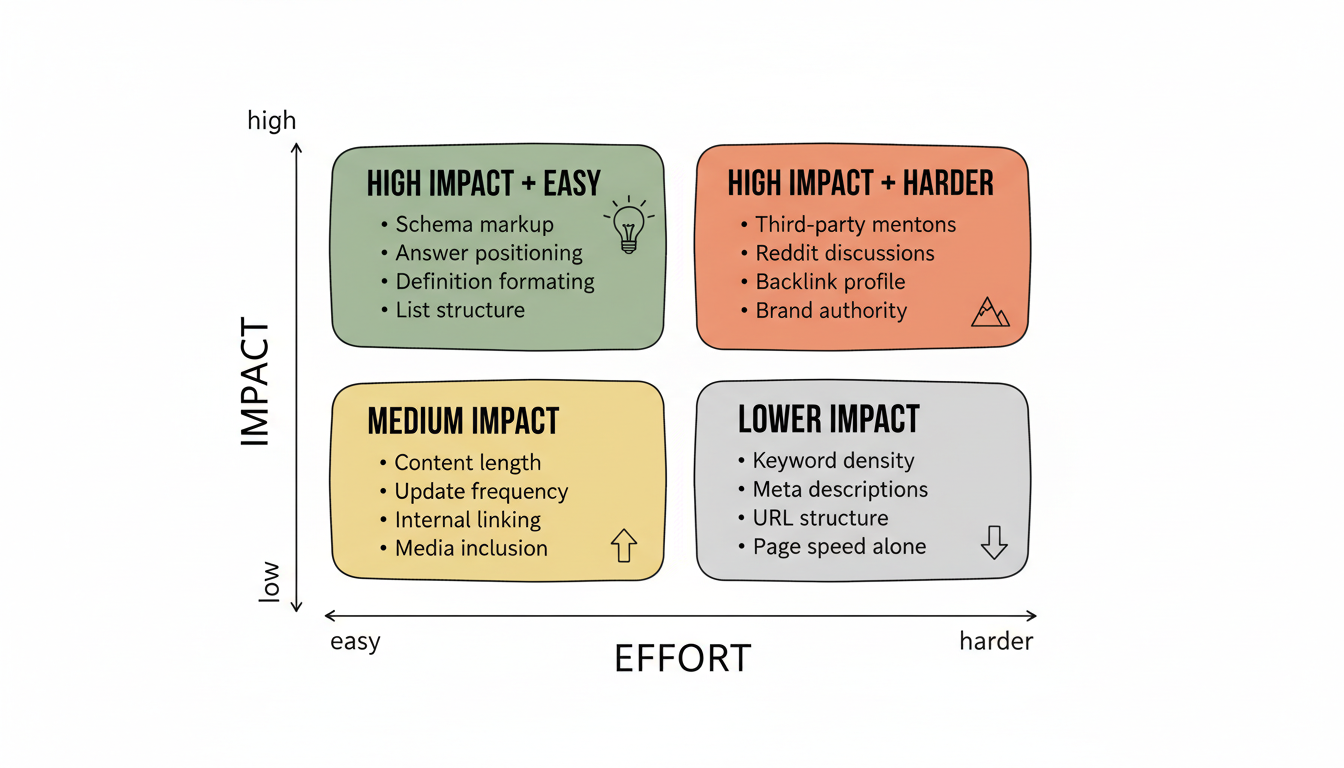
Document current performance before testing.
Baseline metrics to capture:
Metric | How to Measure | Tracking Tool |
Citation count | Manual query testing | Spreadsheet |
AI referral traffic | GA4 AI channel | Google Analytics |
Rich result appearances | Search Console | Rich Results Report |
Featured snippet ownership | SERP tracking | SEMrush/Ahrefs |
Competitor citation rate | Query testing | Manual documentation |
AI search testing requires patience.
Timeline considerations:
Learn from what works for competitors.
According to SEO Sherpa's AI search guide, citation behavior varies between AI tools and affects SEO visibility. Testing should include competitive queries to understand which sources AI platforms prefer for your target topics. When conducting platform-specific AI search optimization, competitive analysis reveals which content strategies work best for each platform.
Competitive testing checklist:
Create institutional knowledge from testing.
According to ALM Corp's Performance Max testing guide, successful testers document learnings meticulously, creating institutional knowledge that compounds over time. Each experiment should inform the next, building sequential testing programs.
Documentation framework:
Test Documentation Template
├── Test Identification
│ ├── Test name and ID
│ ├── Hypothesis
│ ├── Start and end dates
│ └── Test pages/URLs
│
├── Variables Tested
│ ├── Control description
│ ├── Variant description
│ ├── What changed
│ └── Implementation notes
│
├── Results
│ ├── Citation rate (before/after)
│ ├── Platform breakdown
│ ├── Statistical confidence
│ └── Unexpected findings
│
└── Action Items
├── Roll out or revert?
├── Follow-up tests needed
├── Implementation timeline
└── Resources requiredAvoid errors that invalidate results.
Mistakes to avoid:
A/B testing for AI search optimization requires methodology adapted to citation measurement:
According to Marketer Milk's 2026 SEO trends, optimizing for Google allows you to show up in ChatGPT and Perplexity as well—but systematic testing reveals which specific optimizations deliver results across platforms. The brands that develop testing proficiency now will compound their advantages as AI search continues to evolve.
By submitting this form, you agree to our Privacy Policy and Terms & Conditions.