February 19, 2026





AI search systems draw from two fundamentally different information sources: static training data (information learned during model training) and real-time web retrieval (live searches for current information). Understanding this distinction—and how to optimize for each—determines whether your content appears in AI responses regardless of when users ask their questions.
According to Single Grain's LLM freshness guide, LLM content freshness signals determine whether an AI assistant leans on a decade-old blog post or yesterday's update when it answers your query. Understanding how LLMs balance frozen training data with live retrieval reveals what counts as meaningful freshness and how visibility decays over time.
AI search platforms use different mechanisms to answer queries.
According to PageTraffic's AI search guide, in AI search, instead of searching through websites manually, AI will check how reliable and relevant sources are, find useful information, and put together results. AI Search Optimization means designing your content so AI agents can find it, understand it, trust it, and cite it.
AI information architecture:
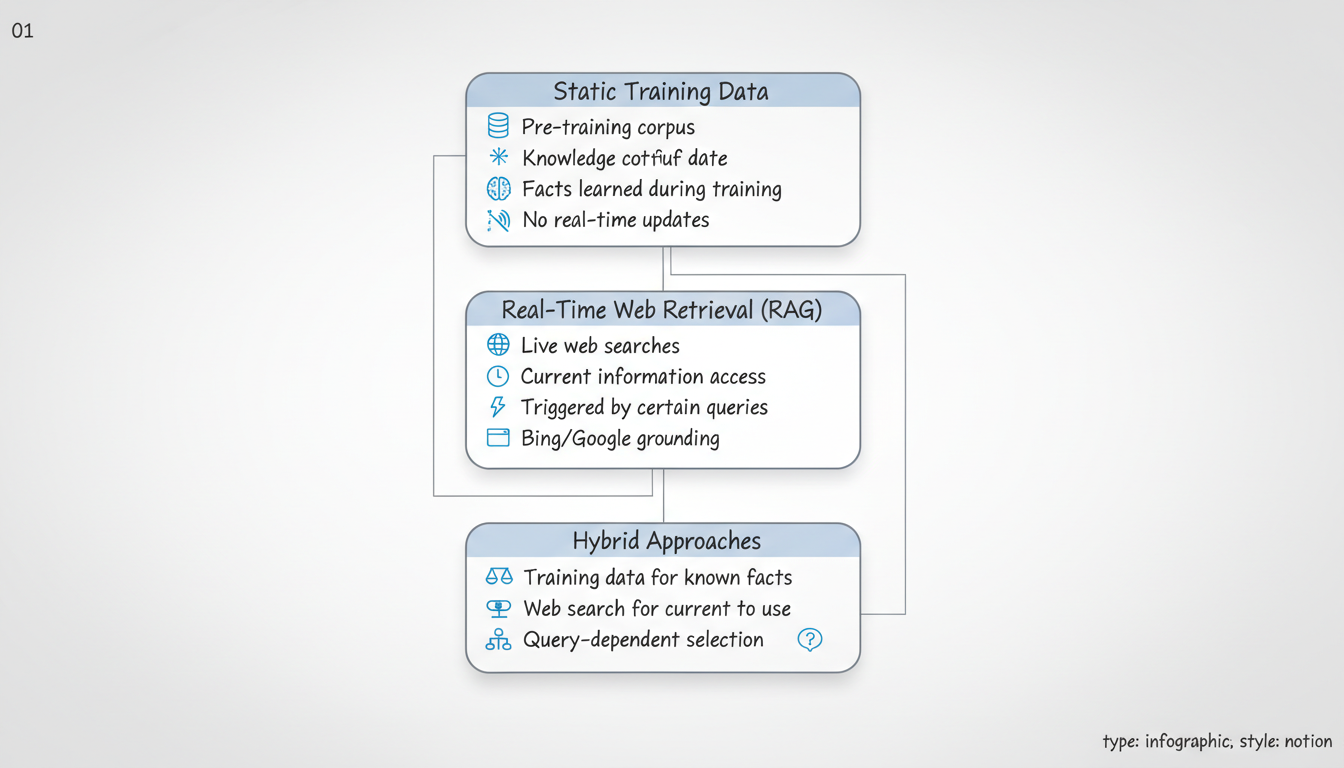
AI Information Sources
├── Static Training Data
│ ├── Pre-training corpus
│ ├── Knowledge cutoff date
│ ├── Facts learned during training
│ └── No real-time updates
│
├── Real-Time Web Retrieval (RAG)
│ ├── Live web searches
│ ├── Current information access
│ ├── Triggered by certain queries
│ └── Bing/Google grounding
│
└── Hybrid Approaches
├── Training data for known facts
├── Web search for current info
├── System decides which to use
└── Query-dependent selectionLLMs contain vast amounts of information from their training process.
According to ViralBulls' ChatGPT ranking guide, while ChatGPT's training data has a cutoff date, its web search capability prioritizes recent, relevant information. Content that was authoritative before the knowledge cutoff may still be cited for timeless topics.
Training data characteristics:
Characteristic | Implication |
Knowledge cutoff date | Information after cutoff requires web search |
Vast corpus | Many sources compete for recognition |
Authority weighted | Well-cited sources during training favored |
Permanent presence | Training data doesn't expire |
Content types that benefit from training data inclusion:
Most AI platforms now incorporate live web search capabilities.
According to Tailored Tactiqs' LLM optimization guide, since AI Overviews and other RAG systems use real-time search to find information, your content's ranking on Google is a strong leading indicator of its potential for LLM visibility. Structured formats like lists and tables boost AI inclusion rates, which is why landing page optimization for AI search has become essential for modern digital strategies.
Real-time retrieval triggers:
When AI Uses Web Search
├── Query Signals
│ ├── Time-sensitive questions ("latest," "2026," "current")
│ ├── Recent events or news
│ ├── Rapidly changing topics
│ └── Explicit recency requests
│
├── Topic Characteristics
│ ├── Fast-evolving fields (tech, AI, markets)
│ ├── Current pricing or availability
│ ├── Recent announcements
│ └── Trending topics
│
└── Platform Behavior
├── Perplexity defaults to web search
├── ChatGPT triggers selectively
├── Google AI Overviews uses live SERPs
└── Copilot grounds in Bing resultsAI systems evaluate multiple signals to determine content currency.
According to Single Grain, LLM content freshness signals are the textual, technical, and behavioral cues that hint at when information was last updated and how trustworthy it is for time-sensitive questions. These signals sit at the crossroads of SEO, analytics, and AI strategy.
Freshness signal categories:
Signal Type | Examples | How AI Evaluates |
Technical | Last-modified headers, sitemap dates | Crawl and index metadata |
Content | Date stamps, "updated" statements | Text analysis |
Contextual | Year references, current events | Semantic understanding |
Behavioral | User engagement, return visits | Indirect quality signals |
Different content types require different freshness approaches. Understanding how agentic AI vs generative AI vs predictive AI systems process content helps tailor your optimization strategy.
Content strategy matrix:
Content Type | Primary Source | Update Frequency | Optimization Focus |
Evergreen guides | Training + retrieval | Quarterly | Authority, comprehensiveness |
Product reviews | Real-time | Monthly | Current accuracy, freshness signals |
News/trends | Real-time | Daily/weekly | Speed, recency indicators |
How-to tutorials | Training | Semi-annually | Clarity, completeness |
Pricing/specs | Real-time | As changes occur | Real-time accuracy |
For content you want embedded in AI knowledge bases.
According to SEOProfy's LLM SEO guide, LLMs prefer content that brings something new because they've been trained on huge amounts of existing material. Original data and insights differentiate citation-worthy content from generic information.
Training data optimization checklist:
For content targeting current queries and time-sensitive topics, generative engine optimization GEO services provide specialized expertise in real-time visibility strategies.
According to PageTraffic, LLMS.txt will become a common rule for helping AI models understand how to explore, read, and use content from websites. This standardization helps content creators and AI developers work together, making search results more reliable.
Real-time retrieval optimization:
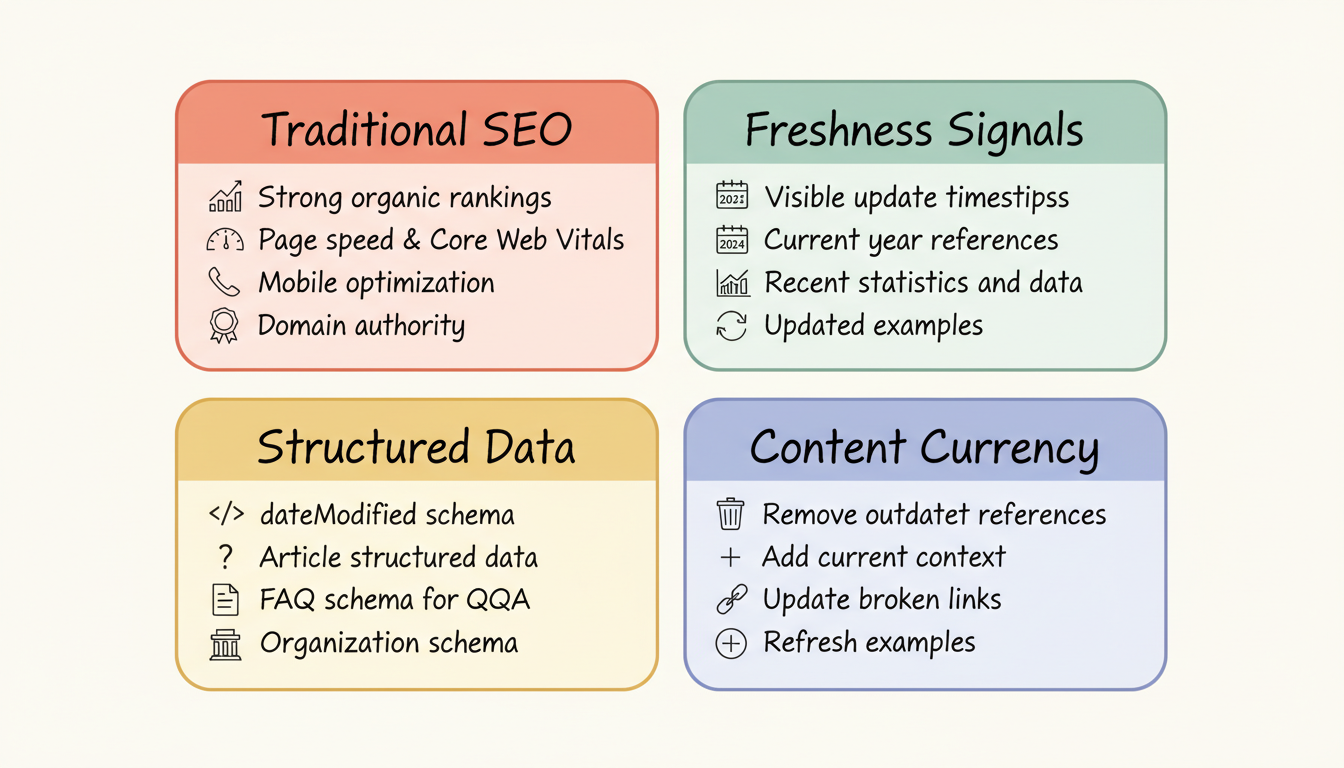
Real-Time Visibility Factors
├── Traditional SEO Foundation
│ ├── Strong organic rankings
│ ├── Page speed and Core Web Vitals
│ ├── Mobile optimization
│ └── Domain authority
│
├── Freshness Signals
│ ├── Visible update timestamps
│ ├── Current year references
│ ├── Recent statistics and data
│ └── Updated examples
│
├── Structured Data
│ ├── dateModified schema
│ ├── Article structured data
│ ├── FAQ schema for Q&A
│ └── Organization schema
│
└── Content Currency
├── Remove outdated references
├── Add current context
├── Update broken links
└── Refresh examplesDifferent AI platforms balance static and real-time data differently. For instance, ChatGPT search optimization requires understanding its selective web search triggers, while You.com AI search optimization prioritizes real-time retrieval by default.
Platform comparison:
Platform | Data Approach | Optimization Priority |
ChatGPT | Selective web search | Authority + freshness for time-sensitive |
Perplexity | Web search first | Real-time SEO, recency signals |
Google AI Overviews | Live SERP grounding | Traditional SEO + structured data |
Microsoft Copilot | Bing grounding | IndexNow, Bing optimization |
Claude | Training data primarily | Authority, foundational content |
Balance freshness with efficiency through systematic updates.
According to Single Grain, a practical framework for prioritizing updates ensures your most valuable pages keep appearing in AI-generated answers. The framework should cover both evergreen and time-sensitive content sustainably. Using AEO checker tools can help monitor which content requires updates based on AI citation patterns.
Update prioritization framework:
Priority | Content Characteristics | Update Approach |
Critical | High-traffic, time-sensitive, competitive | Monthly review |
High | Important revenue drivers, fast-changing topics | Quarterly updates |
Medium | Moderate traffic, slower-changing | Semi-annual refresh |
Low | Low traffic, evergreen | Annual review |
Track how content currency affects AI visibility. Comparing tools like Search Atlas vs Frase vs SEO AI can help identify which platforms best measure freshness signals and AI citation performance.
Freshness measurement approaches:
Avoid errors that undermine freshness optimization.
Mistakes to avoid:
Mistake | Problem | Solution |
Updating dates without content changes | AI may detect thin updates | Make meaningful changes |
Ignoring dateModified schema | Misses technical freshness signal | Update schema with content |
Removing evergreen content | Loses training data presence | Keep timeless material |
Over-optimizing for freshness | Neglects foundational content | Balance both approaches |
Effective AI search optimization addresses both static and real-time data sources:
According to Omnius' GEO Industry Report, GEO is the practice of optimizing content to appear in AI-powered answers rather than traditional search results. Understanding how AI systems source information—from both training data and live retrieval—enables optimization strategies that work regardless of which data source the AI selects. Implementing QAPage schema for AI content and organization schema in your knowledge graph helps AI systems understand and cite your content more effectively across both static and real-time data sources.
By submitting this form, you agree to our Privacy Policy and Terms & Conditions.